Analyzing Vocables in Rap: A Case Study of Megan Thee Stallion*
Zachary Wallmark
KEYWORDS: Rap, voice, timbre, corpus, Megan Thee Stallion, vocal fry, gender, sexuality, branding, “WAP”
ABSTRACT: This article examines the structural and semiotic functions of vocables in rap music. Analytical studies of the rapping voice have predominantly focused on lyrics, rhyme, accent, rhythm, and the emergent property of flow. Although timbral aspects of the voice play an important role in rappers’ flow, identity construction, and reception, investigations of timbre and non-lexical expression (e.g., vocables) remain comparatively rare. As a case study, I focus on the signature ad-lib vocable of Houston rapper Megan Thee Stallion—a creaky-voiced [æ] vowel, like the “a” in cat. Analyzing a corpus of all recorded instances of this vocable in her commercially available recordings (699 instances in 101 songs), along with timbral and phonetic close-reading, I claim that vocables can serve both percussive and formal functions in rap music. Synthesizing perspectives from sociolinguistics, gender and sexuality studies, and brand theory, I argue that Megan Thee Stallion uses her vocable as a timbre trademark: a unique, memorable, and immediately recognizable sonic icon of her brand persona. This brand is closely associated with the gendered and racialized social history of vocal fry in representations of female sexual pleasure. I close by suggesting that vocal timbre plays a leading though often invisible role in hip-hop expression and politics.
DOI: 10.30535/mto.28.2.10
Copyright © 2022 Society for Music Theory
Video Example 1. Opening of Cardi B and Megan Thee Stallion’s “WAP” music video (2020; clean version); Megan Thee Stallion vocable at 0:14

(click to watch video)
[1] In August of 2020, rappers Cardi B and Megan Thee Stallion released their much-anticipated collaboration, “WAP.” A carnal romp set against the backdrop of a socially distanced summer, the song was a megahit, debuting at number one on the Billboard Hot 100 charts and setting the US record for most streams within the first week of release. Based on a looping sample from Baltimore DJ Frank Ski’s “Whores in This House” (Ski 1993), there’s nothing at all subtle about its irreverent, playful celebration of female sexuality, as evinced in the opening of the music video (Video Example 1). Quickly escalating into a cultural flashpoint, conservative figures condemned the song as “disgusting and vile,” with Fox News’s Tucker Carlson entreating his audiences to “go online right now and look up the lyrics to this
[2] The “WAP” controversy, though short-lived, represents arguably the most full-blown moral panic over American popular music in over a decade. Commentators on both sides rushed to the “deliciously filthy” lyrics to justify their strong feelings, but few observers acknowledged the non-verbal elements contributing to the song’s perceived vulgarity—specifically, an instantly recognizable vocal ad lib by Megan Thee Stallion (Video Example 1 at 0:14). At the end of the opening 4-bar hypermeter following Cardi B’s introductory lines, Megan Thee Stallion introduces her presence on the track with a distinctive vowel sound on the “and” of beat 4, followed immediately by an ominous octave drop in the bass. Hyperallergic music critic Lucas Fagen (2019) characterizes these “pugnacious and feminine” gestures as “creaky-voice ad-libs that sound like she’s sticking out her tongue.” By analyzing the inchoate claim on musical meaning embodied in rap vocables—taking Megan Thee Stallion’s ad-lib vocable as a case study—this article argues that manipulations of non-verbal vocal timbre can serve a crucial form-bearing, brand-defining function in rap music.(1) It isn’t just the imagery and the words of “WAP,” and many similar songs, that listeners are reacting to: the timbre of this vocable, and the protruding tongue that always accompanies it, is arguably just as “filthy” as the words. (Although this article is not about “WAP” specifically, I’ll briefly address this song again in the conclusion below.)
[3] Since rap music is such an intensely verbal medium, its discourses tend to foreground its linguistic and lyrical elements (e.g., Bradley 2009). While this orientation is undoubtedly vital, it nevertheless imposes a logocentric hierarchy on rap music practices, placing semantic content at the apex of hip-hop creativity (and controversies).(2) Other writers have inverted this implicit hierarchy by privileging the rhythmic elements of rapping, including phrase structure, accent pattern, and the broader emergent property of flow, which Kyle Adams (2009, para. 1) defines as “all of the ways in which a rapper uses rhythm and articulation in his/her lyrical delivery” (see also Krims 2000; Ohriner 2019). Advocating this general approach, Adams (2008) suggests disregarding the lyrics themselves in the initial reading, focusing instead on the rapped voice as a percussion instrument that interacts in various ways with the underlying structure of the beat. Recent work has also shown that vocal pitch can play an important role in rap flow (Komaniecki 2020).
[4] One area of rap studies that has received far less scholarly attention, however, is the contribution of vocal timbre to rappers’ personal style, narrative, flow, and reception. Unlike words and rhythms, the grain of vocal timbre is specific to the body producing it; hence, as described by Victoria Malawey (2020), a basic tension between language and embodiment is fundamental to many accounts of popular music vocality. For instance, Aaron Fox (2004, 272) distinguishes between two modes of popular vocal expression, poetic (verbal) and phatic (non-verbal), which he describes as the “aural and visceral presence of the vocalizing body in language, calling attention to the physical medium of the voice.” He notes that phatic gestures “may even eclipse the referential content of expression in highly embodied and sense-interrupting forms like vocables, yodeling, melisma and polyphony, and iconic vocal articulations,” aspects of vocality that foreground the unique agency and physicality of the vocalizer. As with all discourses of embodiment, the phatic voice interacts closely with the social logics shaping our notion of what constitutes “the body,” matters ineluctably bound up with issues of gender, sexuality, race, ability, and all other salient categories of identity and difference (Eidsheim 2019). In the singing (and rapping) voice, Fox (2004, 273) continues, “a zone of explicit experiment and contemplation” is established through “the fundamental tension in all language use between the context-bound materiality of the utterance and the abstracting (but never fully abstract or decontextualized) textuality of grammatical, semantic, sonic, and interactional structure.”
[5] This “zone of experiment and contemplation” is the native stylistic soil of rap music. Non-verbal, phatic elements are commonplace in rapping, which includes voices that range from raspy (Busta Rhymes) to smooth (Snoop Dogg) to hoarse (Method Man) to nasal (B-Real of Cypress Hill) vocal timbres. Further, the arsenal of timbrally distinct vocables that commonly punctuate rap verses (“ugh,” “ay,” “ha”), augment each rapper’s distinctive vocal performances. George Lewis (1996, 117) argues that Afrodiasporic improvisatory musicians frequently use timbre and other elements of performance to distinguish their sound from others’ and provide listeners an immediate indexical association with their name, thus making the artful and deliberate manipulation of timbre a critical aspect of artistic identity or, as I’ll argue, brand. He notes: “‘sound,’ sensibility, personality, and intelligence cannot be separated from an improviser’s phenomenal (as distinct from formal) definition of music. Notions of personhood are transmitted via sounds, and sounds become signs for deeper levels of meaning.” In rap, sound is conveyed through the voice: as rapper Guru tells us in Gang Starr’s “Mostly Tha Voice” (1994), “A lot of rappers got flavor, and some got skills / But if your voice ain’t dope, then you need to chill.” In addition to the poetic and rhythmic skills often discussed in rap music discourse, then, phatic expression of the voice, largely governed by timbre, plays a vital though undertheorized role in hip-hop expression, articulating rappers’ individual sounds and brand personas.
Audio Example 1. Megan Thee Stallion’s [æ] vocable
[6] In this article, I examine one site of phatic rap vocality that, despite its ubiquity, commonly escapes scholarly attention: ad-lib vocables. Vocables have certain advantages in the study of rap vocality because they are, by definition, paralinguistic; they comprise “nonverbal voice qualities, voice modifiers and independent utterances” (Poyatos 1993, 6). Analogous to Adams’s (2008, 2009) method of bracketing off vocal rhythms from lyrical content for the sake of analysis, vocables thus provide an opportunity to explore the workings of timbre without being confounded by linguistic referentiality. I want to investigate how timbral elements in rapped vocals, as exemplified in the vocable, contribute not only to the structure of rap songs, but to the broader social semiotic field of artists’ branding and reception. I argue that vocables can, just like rhyme scheme and flow, play a systematic role in the shaping of a rap song’s form. To substantiate this claim, I’ll focus on the music of Houston rapper Megan Thee Stallion (Megan Jovon Ruth Pete), whose signature use of vocables represents a particularly fertile case study for this kind of phatic analysis. Praised by Rolling Stone for her “rich, deep, molasses-filled, and nimble” voice (Holmes 2020), Megan has emerged since around 2018 to become one of today’s most commercially dominant and influential rappers.(3) Her manipulation of a single vocable—the [æ] vowel (like the “a” in cat), produced with vocal fry, as presented in isolation as Audio Example 1—embodies a number of dynamic negotiations that reflect the evolving discourse of sexuality, gender, and race in 21st-century America.
[7] The remainder of this article follows two tracks. First, I will attend closely to Megan’s use of this vocable through phonetic and timbral close-reading, statistical description, and discussions of representative songs to consider how the vocable works in musical context. I will roughly follow the integrative analytical outline developed elsewhere (Wallmark 2022), which charts the pathway of timbre from sound-generating acts to acoustics, perception, and semantics, leading to interpretation within a specific sociohistorical context. My analyses will also be aided with a “microcorpus” of all recorded instances of the [æ] vocable in her music. (I define the term “microcorpus” in paragraph 18 below.) Corpus methods offer an expansive analytical tool for quantifying musical patterns in rap (Ohriner 2019); however, to my knowledge, these methods have not yet been applied to timbral features of hip-hop vocality. Summarizing the corpus data, I argue that Megan most often uses the vocable in percussive contexts—for local rhythmic punctuation—and to demarcate formal boundaries between song sections, typically by way of hypermetrical anticipation (the “and” of beat 4 in measure 4, as in the previous “WAP” example).
[8] Shifting focus, in the second part of the article I build on these data-driven analytical observations to interrogate how vocality and timbre can function as a carrier of gendered and racialized brand meanings in hip-hop. Synthesizing several recent themes in the North American discourse of feminine vocality, specifically the contradictory links associating vocal fry with both “girl speech” and pornographic sexuality, I argue that Megan’s [æ] vocable embodies what hip-hop feminists Aisha Durham, Brittney Cooper, and Susana Morris (2013, 724) dub “percussive feminism,” an attitude of defiant self-possession, sexual empowerment, and autonomy that is “both disruptive and generative.” In Megan’s hands, that is, the vocable is more than just a sound or a noise: as one fan on YouTube commented, “the ‘æh’ is a whole mood.”(4) I examine the considerable cultural work of the vocable through the framework of branding—as a “dynamic, designed system of signs that mediates the relationship between producers and consumers” (Samples 2016, 288). Consolidating the polyvalent social and political meanings already attendant on this specific vocal gesture, Megan Thee Stallion’s creaky [æ] vocable functions as a kind of timbre trademark, an immediate, memorable, and distinctive reference to the artist herself and to the broader constellation of semiotic associations that resonate affect, identity, and empowerment between her “Hot Girl” persona and “Hottie” followers.(5)
Ad-Lib Vocables in Rap
Audio Example 2. Grandmaster Flash and The Furious Five, “Freedom” (1980), 7:48–8:08
[9] Megan Thee Stallion frequently punctuates her verses with a range of ad-lib vocables such as “ay,” “huh,” “yeah,” “mwah,” “ugh,” “hey,” “whoa,” and “baow,” gestures that are common currency among rappers. In rap songs, ad libs are generally integrated into a secondary vocal track or series of punch-ins that interact antiphonally with the main vocal. Secondary vocals are often distinguished from the main track through differences in volume level, equalization, effects, and spatial position within the stereo field. The interplay between the two (or more) vocal tracks is commonly characterized by elements of call-and-response: ad-lib vocals provide affective commentary on the local narrative, echoing, emphasizing, testifying, playfully rebutting, or otherwise signifying on a rapped bar. This general approach to non-verbal vocal expression has a long history in Afrodiasporic cultural practice (Southern 1983, Keyes 2002). Olly Wilson (1999, 160) notes the “myriad of vocal sounds used in [Afrodiasporic] performance (moans, groans, yells, screams, shouts, shifts in sonority),” concluding that these “textless, single-line interjections illustrate with expressive brilliance the significance of timbral nuance in [B]lack music” (165). In the hip-hop context, non-verbal expression and interplay of this sort has been common since the earliest days of collective MCing in the late 1970s, where each rapper’s turn at the mic was supported by the background vocable ad libs of their peers. To illustrate, Audio Example 2 presents the outro to Grandmaster Flash and the Furious Five’s “Freedom” (1980), which features a verse from rapper Cowboy supported by ad-lib vocables from Melle Mel, Mr. Ness, King Creole, and Raheim.
Audio Example 3. Megan Thee Stallion, “Shots Fired” (2020), 0:00–0:03
[10] During the 1980s and 1990s, when rapping morphed into a predominantly recorded, solo form, many of these dialogic gestures were retained in the form of ad-lib tracks consisting primarily of paratextual interplay and vocables overdubbed by the rapper in conversation with their own primary vocal track. Moreover, in addition to responding to local features of the narrative (e.g., a specific rhyme), rappers sometimes use vocables to reinforce global semantic features of a song. For example, “Shots Fired”—Megan’s response to the experience of being shot in the foot by an acquaintance in 2020, which samples The Notorious B.I.G.’s “Who Shot Ya?” (1994)—opens with ad libbed onomatopoetic gun shots (Audio Example 3).
Example 1. Megan Thee Stallion, “Circles” (2020), 0:17–0:21

(click to enlarge and listen)
Example 2. Megan Thee Stallion, “WTF I Want” (2018), 0:30–0:43

(click to enlarge, see the rest, and listen)
[11] In keeping with the principle of call-and-response, ad-lib vocables in rap songs generally appear at line ends, as in the chorus of “Circles” (vocal rhythm transcribed in Example 1; vocables highlighted in blue).(6) In some cases, however, rappers shift the response vocable onto stronger parts of the beat. For instance, Example 2 presents part of the first verse of “WTF I Want” (2018). Here, Megan punctuates each antecedent and consequent pattern of her triplet-inflected flow with the vocables “huh,” “ugh,” “ay,” and “woo” that emphasize beats 1 and 3, thereby inverting the standard call-and-response ad lib pattern. The main vocal in this example is heard as a response to the call of the insistent, percussive vocables. (I should warn readers at this point that Megan’s lyrics, excerpts of which are transcribed without alteration throughout this article, are often explicit.)
Defining the [æ] Vocable: Phonetics and Acoustics
[12] Most of Megan Thee Stallion’s arsenal of vocables and rhythmic techniques can readily be found in the work of other emcees. However, one specific non-lexical vocal gesture stands out as central to her sonic persona, appearing in virtually all her songs—an isolated [æ] vowel, pronounced like the “a” in cat. (For clarity, I will adopt the [æ], or “ash,” symbol enclosed in square brackets, from the International Phonetic Alphabet.) Megan’s [æ] vocable is characterized by two primary features: first, it’s very short, less than 100 milliseconds for the main phonation typically followed by 200–300 milliseconds of decay, depending on reverberation. Second, it’s always voiced in the paralinguistic register of vocal fry.(7)
Video Example 2. Megan Thee Stallion saying [æ] GIF

(click to watch video)
[13] In phonetics, the [æ] sound is classified as a near-open front unrounded vowel (Laver 1994). “Near-open” refers to the vowel height, or vertical position of the tongue. Open vowels feature a low tongue position—like the doctor telling you to “say ahh”—leading to a wide-open mouth. The [æ] vowel sits close to this lowest vertical position. “Front” refers to the horizontal position of the tongue in the mouth (or vowel backness). Front vowels such as [æ] are produced with the most forward oriented tongue position available in standard American English. Finally, “unrounded” speaks to the shape of the lips during articulation. Taken together, the phonetic markers of this vowel suggest an open mouth with unrounded lips and protruding tongue. The motor image suggested by music critics (e.g., Fagen 2019)—the sound of sticking out a tongue—is isomorphic to its phonetics.
Example 3. Emoji tweet (August 29, 2019); cover images of Suga (2020) and “WAP” (2020; Cardi B feat. Megan Thee Stallion)
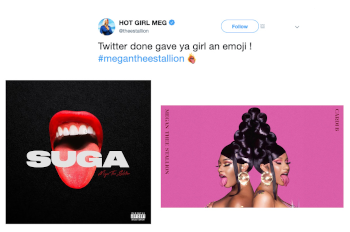
(click to enlarge)
[14] We don’t need to go far to see how this mouth position plays out in context. Megan’s self-presentation—including live performances, album covers, music videos, publicity shots, and videos and pics posted on social media—is replete with performative, exaggerated versions of a near-open front unrounded [æ] vowel, as compiled by a fan into the amusing GIF presented in Video Example 2. In the “Hot Girl Summer” of 2019—named after her self-labeled “Hot Girl” persona and fans—Twitter launched the #megantheestallion emoji of a protruding tongue surrounded by flames, which later inspired the cover image of her Suga EP (2020). The [æ] tongue gesture is also featured in the “WAP” (2020) cover image performed by her and collaborator Cardi B (Example 3). As Nylon writer Sesali Bowen (2019) explains, “We do not support reducing women to their body parts, but Megan’s tongue is important. First of all, it is the vehicle for her creatively sharp bars. It’s also often on display, especially when she delivers her signature ad-lib: ‘agh.’” As I explore later, the [æ] vocable is thus a crucial component to Megan’s lyrical, sonic, and visual brand, serving iconically to unite these three frames of reference. Founded upon the basic phonetic components of the vocable, hearing her intone [æ] also has the effect of immediately referring the listener to a web of associated images and actions, as well as perhaps evoking a motor echo of producing this vowel and timbre oneself (Heidemann 2016). Conversely, images such as those in Example 3, familiar to any fan, are baldly crossmodal, summoning in the auditory imagination the vocable [æ]. One is a stand-in for the other.
[15] In addition to the phonetic properties of the vowel itself, Megan’s vocable is heavily inflected with vocal fry. The voice has four natural registers: modal (regular speech and singing), falsetto (sometimes referred to as “loft”), whistle, and vocal fry (“pulse”, or more clinically, laryngealization).(8) Vocal fry is produced by activating a loose glottal closure with low air flow, causing the vocal folds to flap unpredictably as air pulses proceed through the opening of the larynx. Consequently, the fundamental frequency of the voice drops, and the timbre takes on a popping, grainy quality. This paralinguistic register has been described in vivid metaphorical terms, as “a rapid series of taps, like a stick being run along a railing” (Catford 1964, 32), and “bacon sizzling in a pan” (Habasque 2019, 4). Fans have offered their own descriptions of Megan’s signature vocable: for example, one YouTube commenter observed, “It sounds like those spring thingies on the wall near the floor.”(9) Unlike modal or loft register, there is an inherent temporal dynamism to vocal fry. As Serge Lacasse (2010, 144) notes, “we can hear the clicks subdividing the sound event at a microacoustic level.”
Example 4. Waveform (top) and spectrogram (bottom) of Megan Thee Stallion’s [æ] vocable
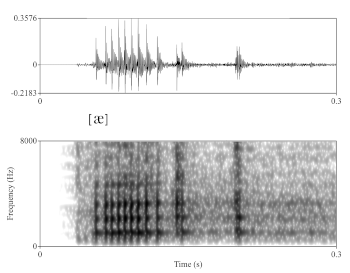
(click to enlarge)
[16] A creaky timbral quality is readily apparent in acoustical analysis of Megan’s [æ] vocable. As shown in the waveform and spectrogram of Example 4, vocal fry is characterized by discrete glottal pulses, approximately nine of which are identifiable in her recordings (followed by a few additional irregular pulses).(10) Moreover, the energy spectrum is fairly evenly distributed, extending to above 6000 Hz; while fry significantly lowers the fundamental frequency, it’s also characterized by high-frequency noise elements. Besides the phonetic and acoustic characteristics of this vocal register, vocal fry is also a multivalent sociophonetic cue that has been fiercely contested in recent American media, a point that we’ll return to in depth later.
The [æ] Microcorpus: Quantifying Prevalence and Function
[17] Just how frequent is the [æ] vocable in Megan Thee Stallion’s songs, and how does she use it in musical context? To accurately generalize about the vocable, I’d like to first characterize the broader patterns of usage across her recorded output. Hirjee and Brown (2010), Condit-Schultz (2016), and Ohriner (2017; 2019) have applied computational tools to analyze rhyme patterns, rhythmic devices, and lyrical norms in moderately large corpora of rap songs. Methodological advances by these and other corpus scholars have enabled the analyst a bifocal view of flow in rap, an ability to toggle between local patterns (within individual songs, artists, subgenres, time periods) and larger statistical generalizations (between songs, artists, etc.). Ohriner (2019, xxiii) describes a key strength of this approach as establishing, in data-driven terms, the “rules of the game” operating in a given style while “avoid[ing] a host of implicit biases and praxes in human analysis.” Here, with truncated ambitions, I discuss a microcorpus consisting of all [æ] utterances in Megan Thee Stallion’s commercially available discography. (The dataset and R analysis script is available for download, per the humanities data-sharing recommendations of Ohriner (2019, xxxiii–v), at https://bit.ly/31cwkZR.) Applying simple statistical measures to the microcorpus illuminates global usage patterns and motivates further questions concerning the function and meaning of this vocal timbre.
[18] A brief note on method is warranted. I want to distinguish my term “microcorpus” from simply a small corpus.(11) Most music corpus projects, regardless of their size, have at their core the goal of representativeness; that is, sampling a subset of the total population (e.g., all rap songs) that statistically stands in for the whole. A microcorpus, in contrast, contains every observation within a (comparably small) population—it’s not representative, but complete—thus subtly shifting the analytical assumptions away from statistical inference and toward description and interpretation, or as Huron (2013) calls it, “empirical hermeneutics.” The knowledge to be gained from the microcorpus is limited only to this artist and is not generalizable to all vocables in rap. However, patterns found in the total recorded output of one influential performer can provide the empirical grounding to tackle analytical and interpretive questions that would otherwise be difficult to address if based solely on the analyst’s personal preferences and samples of convenience. Thus, I use the microcorpus with a good deal of humility as a provisional basis for grounded interpretation, most certainly not as a validating, axiomatic truth; this is especially important to point out given the complex history of music-theoretical engagements with Black American popular music (Krims 2000, chapter 1). As statistician Nate Silver (2012, 9) notes, “The numbers have no way of speaking for themselves. We speak for them. We imbue them with meaning.” It’s this spirit that animates the current corpus.
Example 5. Data collected for the [æ] microcorpus

(click to enlarge and see the rest)
[19] The microcorpus consists of the [æ] vocable with fry inflection; other vocables were not included. I manually encoded every instance of the [æ] vocable along with the information listed in Example 5 across Megan’s two full-length albums, three EPs, one mixtape, and twenty-four guest tracks (as lead or featured artist) released between 2017 and November 2021. In total, the microcorpus encompasses 699 uses of the vocable across 101 songs.
Example 6. Frequencies of the [æ] vocable by year
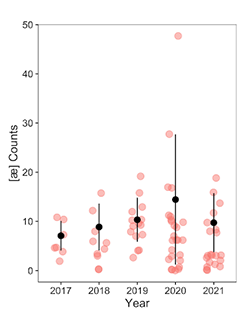
(click to enlarge)
[20] As one YouTube commenter posted, “It’s not a Megan song if she doesn’t say ah at least five times.”(12) How accurate is this statement? Across recordings released under her name (i.e., excluding guest verses as featured artist), Megan says [æ] an average (mean) of 7.46 times per song, though this number can vary widely (standard deviation = 7.19): the highest frequency is 48 (“Body”), while seven more pop-oriented songs (and two skit tracks) don’t include the vocable at all.(13) Its prevalence has been remarkably consistent since the beginning of her recording career: Example 6 shows vocable counts in all songs released under her name (red points); the black points are mean frequency per year, and error bars represent the standard deviation of the mean. It appears that this YouTube comment is fairly close to the mark: Megan’s trademark vocal sound is a defining—perhaps the defining—characteristic of her sound.
[21] Surveying the microcorpus, two general categories of the [æ] vocable dominate Megan’s flow, what I’ll call percussive and formal uses. Although these gestures are clearly exemplified in her music, they are not at all unique to it; rather, the percussive and formal devices described here are widespread among rappers and largely representative of how vocables are commonly integrated into rap songs. Though these categories sometimes overlap, they nevertheless describe the broad functional strokes of both Megan’s iconic sound and the larger field of vocables in hip-hop.
Percussive vocables
Example 7. Megan Thee Stallion, “Work That” (2020) chorus (0:25–0:30)
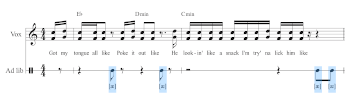
(click to enlarge and listen)
[22] I define a vocable as percussive when the sound is used to accent the flow in a manner analogous to any percussion instrument or sample, typically in small local rhythmic groupings (between 2–6 eighth notes).(14) In many instances in Megan’s work, percussive vocables are sampled (i.e., pre-recorded) rather than recorded “live” in the context of a secondary ad-lib track.(15) In terms of flow, this category is aligned with what Krims (2000, 50) refers to as the “percussion-effusive” style of rapping characterized by a “combination of off-beat attacks with a sharply-attacked and crisp delivery.” However, since percussive vocables in Megan’s songs are often sampled then pasted into a track, not ad-libbed in real time, it’s perhaps less a matter of flow per se than of production. Percussive vocables usually bear a weak association to the structure of a song: while they punctuate the flow at a local level of organization, they don’t typically delineate the form. To briefly illustrate, Example 7 presents part of the chorus to “Work That” (2020; produced by Juicy J Z3N), which integrates percussive [æ] vocables (blue) into a call-and-response pattern with the main vocal. Close to half (43%) of the microcorpus consists of what I hear as percussive vocables.
Example 8. Megan Thee Stallion, “Body” (2020) chorus (0:10–0:30)
(click to enlarge and listen)
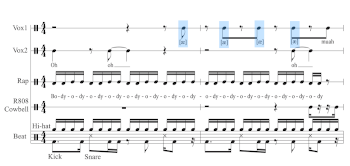
[23] The percussive style is exemplified in the single “Body” (2020; produced by LilJuMadeDaBeat), a sex-positive club anthem written by Megan during the early days of the COVID-19 lockdown. Example 8 presents a transcription of the eight-bar chorus with percussive [æ] vocables highlighted in blue (Vox1). The first two bars feature four consecutive [æ] off-beats starting on beat 4 of measure 1, immediately followed by a percussive kiss sound; this pattern is then repeated in mm. 3–4. In other words, the [æ] vocable is integrated into the fabric of the beat, akin to the way a producer might add any repeating element into the beat matrix, such as the Roland TR-808 cowbell hits notated in the transcription. Following the opening, in mm. 5–6 the [æ] is replaced by creaky-voice “ya” vocables on off-beats. Additionally, another non-verbal vocal track features prominently in this chorus and throughout the song: a feminine moan sampled from a pornographic film, here notated as Vox2.(16) (Lest there be any doubt, these connotations are made explicit in the introduction, when we hear mechanical sounds of a reel-to-reel film projector along with the moaning. We’ll return to these semiotic associations later.) The song features three additional iterations of this chorus, each with different configurations of these core vocal elements. Even the ostensibly verbal main vocal track is leached of semantic content and transformed into a vocable through extreme repetition of the word “body” (-ody-ody-ody) in mm. 1–4 and 7–8. Taken together, the chorus offers an interplay of non-verbal vocal displays, punctuated by several percussive vocables, and bookended by the [æ] trademark. In a crucial sense, the prominence of repetitive vocables in this chorus draws attention to the phatic elements of Megan’s vocality, the female-gendered body behind the voice, with tongue out, rather than the poetic capacity of the lyrics. These vocables contribute to a net impression of sexual abundance and excess. In short, the chorus of “Body” is more lingual (related to the tongue) than linguistic.
Formal vocables
[24] Comprising roughly the other half of the microcorpus (51%), I define formal vocables as cases where the sound demarcates the sectional boundaries of the song’s form, most commonly as a transitional element between intro and chorus, chorus and verse, verse and outro, prechorus and chorus, and so on, but also to subdivide longer sections such as a verse. Formal vocables frequently appear as a single statement on the hyper-downbeat, or, much more commonly, an anticipation of the new phrase on the “and” of beat 4. They also regularly appear in small local groupings. Although the line between percussive and formal vocable is not always crisp, the main distinction between the two is that formal vocables generate a kind of teleological tug: they cue the listener to expect a fresh musical section. While percussive vocables most commonly provide rhythmic accents at a more local level of organization, formal vocables convey information about the global structure of a song.
Example 9. Megan Thee Stallion, “Sugar Baby” (2020) second verse (1:07–1:19)

(click to enlarge and listen)
[25] As evinced in the microcorpus, formal vocables are entirely dependent on rhyme scheme and song form. Many rhymed syllables in rap occur on beat 4 (Adams 2009; Condit-Schultz 2016; Ohriner 2019). This is often the case in Megan’s flow: for example, Example 9 presents two beat-4 end-rhyme couplets in “Sugar Baby,” with rhyming syllables highlighted in red (ticket/dick is, attitude/wanna do). Placing [æ] at the end of beat 4 (blue) immediately following the resolution of the rhyme, this representative gesture engages in clear call-and-response, answering the two preceding couplets with a non-verbal vocal accent.
Example 10. Frequency of the [æ] vocable in each metrical position of the 4-bar hypermeter]
(click to enlarge and listen)
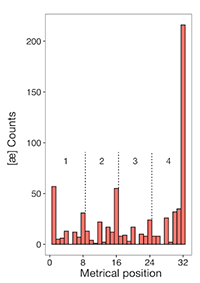
[26] In addition to accentuating or amplifying individual rhymes, the anticipation on the final eighth note of the phrase sets up the next musical unit, thus serving a transitional function (here, to the second half of the verse). The overwhelming majority of Megan’s songs are organized around a 4-bar hypermeter consisting of two consecutive rhymed couplets. To be sure, this is the most common formal schema in rap songs. Subdivided by eighth notes, this 4-bar phrase therefore consists of 32 metrical positions: Where does the vocable most frequently occur within this metrical structure? Example 10 displays a histogram of counts of the vocable within the hypermeter. Exactly one-third of all [æ] vocables in her songs occur as an anticipation on the final eighth note of the final measure of the four-bar phrase. David Temperley (2021, 26) refers to this placement as “anticipatory fourth-position syncopation.” In a corpus analysis of syncopation in American popular music, he found that this pattern has no historical precedence prior to the emergence of ragtime around the 1890s, and is likely derived from Afro-Caribbean influences. In Megan’s recordings, this placement dwarfs all others in frequency: the second most common positions, each accounting for around 9% of occurrences, are the hyper-downbeat (position 1/32) and the final eighth note of measure 2 (position 16/32). All other metrical positions are infrequent (5% or fewer occurrences).
Example 11. Frequency of [æ] vocables in each song section
(click to enlarge and listen)
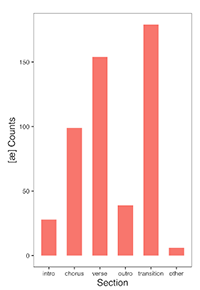
[27] Considering that anticipatory fourth-position syncopation is by large margin the most common placement of the [æ] vocable within the hypermeter, it’s clear that Megan and her producers use this gesture to provide structural signposts in moments of heightened attention and formal salience. In short, the [æ] vocable functions as a kind of form-delineating glue that binds together the discrete sections of her songs. Example 11 indicates the frequency of the vocable within main song sections, along with instances where Megan uses the vocable to transition between these sections. Over one-third (35%) of all [æ] vocables in the microcorpus (and 60% of all formal vocables) delineate sectional boundaries, while 30% occur within verses, 20% within choruses, 8% within outros, and 6% within intros.
[28] Another contextual measure of emphasis or accentuation can be found in the relation of the vocable to a common production technique in hip-hop beat-making, a one- or two-beat exclusion of the accompaniment, especially drums. By way of illustration, the “Sugar Baby” verse (Example 6) features such dropouts in mm. 1, 2, and 4; “Work That” (Example 7) in m. 2; and the “Body” chorus (Example 8) in m. 8. Dropouts are a kind of silent or subtractive accent: by suddenly removing the core instrumental tracks, dropouts momentarily draw attention to the foreground, almost always the vocal track, to create tension and anticipation leading to the resolution of the rhyme and/or transition to another section, with resumption of the beat. Across the microcorpus, 31% of all [æ] vocables are exposed through a dropout of the beat; and of these vocables with dropout, 39% occur during transitions, more than in any other section (32% in verses, 8% in outros, and 6% in choruses).(17) Taken in aggregate, the prevalence and accentuation of the vocable in signaling transitions between sections—transitions that are further underscored in certain instances with beat dropout—strongly implies that Megan and her producers are systematically deploying this vocal gesture to mark out the formal contours of her songs.
Example 12. Form chart of Megan Thee Stallion, “What’s New” (2020)
(click to enlarge and listen)
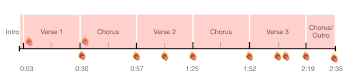
[29] We can make this generalization more concrete by mapping the use of formal vocables across a representative song. Example 12 is a form chart of “What’s New,” from her debut LP Good News (2020). The song has a standard verse-chorus form, and each section except for the final half-chorus/outro consists of two 4-bar hypermeters (subdivided in the chart by the dotted line). I indicate the [æ] vocables with the #megantheestallion emoji. Formal uses of the vocable are below the timeline and percussive uses are within the sectional blocks. “What’s New” has eleven occurrences of the vocable, nine of which are formal. Apart from the first verse following a one-bar intro, every transition between verse and chorus is marked with anticipatory fourth-position syncopation. The second and third verses also feature mid-phrase anticipations, including a double statement in the third verse (m. 2 of the phrase, beat 4 and 4+). Moreover, “What’s New” ends with the [æ] vocable as the final sound of the track, exposed through dropout. The exposed [æ] vocable also occurs in 14 of her songs, including the final songs of both the Fever and Something For Thee Hotties albums.
The Sexual Politics of Vocal Fry
[30] So far in this article I’ve described some phonetic, timbral, and formal features of the [æ] vocable. Shifting focus, I now situate one component of the vocable, namely its vocal fry, within an interpretive, cultural context. There’s a complex backstory to the kind of phatic vocality staged in Megan Thee Stallion’s creaky [æ] vocable that is not readily visible to a corpus approach to music analysis or corpus tools. This technique isn’t a neutral paralinguistic affectation or acoustical ornament. Rather, it’s a sociophonetic register, a communicative strategy to signal important information about speaker identity and social position. It’s also a semiotically multivalent gesture with a long history of associations in North America. These social meanings are crucial to understanding how the vocable functions both musically and within Megan’s Hot Girl brand ecosystem.
[31] In the United States today, the two most important intersecting social fault lines of vocal fry are gender and age. In one of the earliest sociolinguistic studies of creaky voice in Britain, Henton and Bladon (1988) found that it was most prevalent among men who used it to project an exaggerated masculinity, likely due to its lower fundamental frequency compared to modal speech. This connotation is familiar to North Americans as well, of course, from Sylvester Stallone in Rocky to voice-overs for action movie trailers. Suggesting a gender realignment in the American context, however, linguists in the 1990s theorized that young female speakers in the US were adopting fry to sound more authoritative, also because of its lower pitch and implication of masculine power. Summarizing this view, Yuasa (2010) writes, “creaky voice may provide a growing number of American women with a way to project an image of accomplishment (on par with men) while retaining feminine desirability.” Indeed, while average fundamental frequency in modal voice differs by one octave between female- and male-identifying speakers, in the vocal fry register average fundamental frequency is almost identical between such speakers (Hollien 1974). By leveling gender-based pitch differences, it’s plain to see why vocal fry would become a contested site for the negotiation of gender representations.
[32] Although common among both sexes, a recent meta-analysis indicates that vocal fry is generally more widespread among female speakers (Dallaston and Docherty 2020). This perception has been reinforced by commentators in the American media, usually in mocking or scolding terms associated with the “valley girl” stereotype. In one Guardian think piece, for instance, feminist Naomi Wolf (2015) compared the sound of female vocal fry to quacking ducks, and urged young women to “give up on vocal fry and reclaim your strong female voice,” noting studies suggesting that fry “makes young women who use it sound less competent, less trustworthy, less educated and less hirable: ‘Think Britney Spears and the Kardashians.’” While fry is a regular feature of both male and female speech and singing, it tends to be judged more harshly, by both men and women, when women do it.(18) This stigmatization of speech patterns stereotypically associated with women and girls—including talking too much or too loudly, uptalk, “shrill” speech, the quotative use of “like,” and so on—often reflects an androcentric tendency of commentators to view male speech as the normal, unmarked category and female vocality as deviant, a perception that is amplified in cases such as creak that involve sex-atypical pitch modulations (Coates 2015). Accordingly, Habasque (2019, 6) identifies the current reception of vocal fry as a kind of widespread “linguistic misogyny.”
[33] Implicit in the preceding discussion is the association between vocal fry and youth. In addition to younger speakers’ greater proclivity to use fry, older listeners are more likely to perceive the register negatively in both speech and song, leading Chappell and coauthors (Chappell et al. 2020, 156.e10) to conclude that “positive interpretations of vocal fry in music are only accessible to younger
[34] The semiotics of vocal fry can be quite promiscuous, in part owing to this in-betweenness. Linguist Fernando Poyatos (1993, 209) lists a wildly heterogenous set of common meanings: fry inflection is used to express boredom, reluctance, or suppressed rage; to speak in a cutesy way to a baby or pet; by children whining to adults; and by “women talking lovingly to a man in a babyish voice, often referred to as purring.” It’s this last connotation that interests me most. To be sure, though the range of meanings attendant on vocal fry can vary widely, in certain contexts of feminine adult speech, the fry inflection is associated with sensuousness and sexuality. In a study of vocal fry in American film actresses’ speech, Pennock-Speck (2005) found that actresses use fry most pronouncedly in scenes with erotic charge, suggesting that the register is linked to sexual desirability, seduction, and power. This same vocal register, however, can also express gendered sexual excess and indecency. Habasque (2019) analyzed scenes from the TV show Parks and Recreation to argue that fry is used to portray “vulgarity” in a female character who is loud, swears, and discusses taboo sexual topics without social filter. Fry in women, then, is a sign of sexuality. But since female sexual self-expression is socially and politically circumscribed, fry transgresses normative codes of sexual propriety, signaling instead hypersexuality or promiscuity. Moreover, since Black women have long been stereotyped as hypersexual in American culture, this connotation is indelibly linked to the social framing of race. Thus, the burden of fry’s sexualization is typically experienced most acutely, and most destructively, by Black women.
[35] Where does this connection between vocal fry and sex come from? One explanation is proxemic (Moore 2012, 186–7): vocal fry register, produced by low air flow, is generally quieter and does not project as much as standard modal register, thus implying physical closeness and intimacy. But a stronger explanation in American popular entertainment can be located in the conventionalization of vocal fry—especially in concert with paralinguistic utterances such as moans and groans—in the auditory staging of female sexual pleasure. Specifically, in its current form, this semiotic reference likely originated with the rise of pornographic film in the 1960s and 1970s.(19) As Linda Williams (2008) notes, lacking clear visual evidence of sexual fulfilment in a manner analogous to the male orgasm, porn films codified the representation of female pleasure as a “frenzy of the audible.” Jon Stratton (2014, 115) explains: “If women’s sexual pleasure
Audio Example 4. Sylvia Robinson, “Pillow Talk” (1973), 2:32–2:57
Audio Example 5. Donna Summer, “Love To Love You Baby” (1975), 7:20–8:40
[36] This repertoire of audiovisual sex noises soon found its way into Black American popular music.(20) For example, Sylvia Robinson’s “Pillow Talk” (1973) features breathy singing, inhalations, whispers, and creaky groans to sonically convey intimacy and pleasure (Audio Example 4).(21) More theatrically, Donna Summer’s extended disco release “Love To Love You Baby” (1975) consists of a series of build-ups and break-downs structured around the singer’s vocal imitations of sex, as explored in depth by Fink (2005), Stratton (2014), and Heidemann (2016). Audio Example 5 presents the beginning of one of these builds: Summer starts by moaning lightly with a “mmm” or “oh” syllable on beat 2 every other bar before singing the repeating melodic figure, always with vocal fry. Soon, as her staged arousal mounts, the ecstatic groans morph into more mouth-open, tongue-frontal “ah” vowels such as [ɐ] and [ä], which align with the introduction of a heavy thud of the kick drum on beats 2 and 4. This then gives way to a four-on-the-floor kick pattern as her performance builds to an orgasmic frenzy of the audible (then another, and another). Crucially, these recordings offer intense aural stagings of Black female sexuality in a manner that foregrounds the singer’s subjective performance of pleasure, not the implied pleasure they could be offering to a sexual partner. (Though, of course, the listener is situated as the voyeuristic onlooker or ersatz partner in these displays, so the gaze is not completely obviated.) As Mark Anthony Neal (1999, 122) explains of “Love to Love You Baby,” “Summer, as representative of [B]lack women, is transformed from sexual object into sexual subject.”(22)
[37] Megan Thee Stallion clearly inherited this broader semiotic history. Her [æ] vocable draws upon many of these preestablished codes, most notably the position of vocal fry in current debates over the power of young women in society and the contested role of the voice in articulating or forfeiting that power. Further, cross-fertilized with its connotations of sexual subjectivity, Megan seems to imply with her vocable that power and sexuality are closely related. The cover image of the Suga EP (Example 3) encapsulates this dynamic: the open mouth and tongue are glistening and sensuous, framed with fire-engine-red lipstick, a diamond stallion tooth tattoo, and an unmistakable sneer, suggesting total ownership of her sexuality (not to mention a cheeky and teasing quality). Of course, it doesn’t require a fantastical hermeneutic leap to read her imagery, themes, and lyrics—indeed, the entirety of her musical output—into this interpretive framework. Unlike Donna Summer, Megan does not explore sexuality by way of hinting aural intimations of pleasure, but through unapologetically vivid lyrical and visual references, primarily to oral sex, the paragon act of receiving sexual gratification without the necessary implication of mutuality. In short, there’s little ambiguity in the theme of sexual power (or perhaps, power over) that is so viscerally embodied in the creaky [æ] vocable and tongue imagery. To be clear, Megan is neither the first nor only female rapper to explore such topics; New York rapper Lil’ Kim pioneered this mode of brash, vulgar, and witty “Queen Bitch” sexuality in the late 1990s, and a number of successful female rappers have similarly proven themselves to be cunning linguists of cunnilingus (e.g., Khia, Foxy Brown, Nicki Minaj, Trina, Azealia Banks, City Girls, and Cardi B).(23) However, none of these rappers so deftly connect dirty lyrics and imagery with an identifiable vocal timbre that immediately references the semiotics of sex.
Example 13. Word cloud of lyrics preceding the [æ] vocable (frequency of 9+ only)

(click to enlarge)
[38] How does Megan’s vocable align with her lyrics? To get a rough sense for the semantic content most typical of phrases that end with the vocable, we can return to the microcorpus and use text analysis tools to tabulate the words in the couplets immediately preceding each vocable (in linguistic parlance, collocation). Filtering out common function words leaves us with 1,888 words, the most frequent of which are displayed in the word cloud in Example 13, with word frequency corresponding to relative text size (content warning: word cloud contains explicit language). A momentary glance confirms the obvious: across the 101 songs in the microcorpus, the [æ] vocable is connected to several characteristics of the Hot Girl persona, which we explore in the next section, including a proud reclamation of the terms “bitch” (at 85, the highest count) and “ratchet;” references to the body, specifically female sexual anatomy and what the persona would like done to it (“body,” “pussy,” “ass,” “lick,” “eat,” “fuck,” “tongue”); and references to financial independence (“money,” “buy”). To be sure, this analysis does not distinguish these collocations from lines that do not include the [æ] vocable, so these patterns could simply reflect the key words in her flow regardless of context vis-à-vis the vocable. Regardless, the elision of Hot Girl themes and Hot Girl vocable amplifies the vocable’s semantic associations. In addition to serving percussive and formal functions, that is, the [æ] vocable—and the “percussive” feminist attitude it embodies (Durham, Cooper, and Morris 2013)—frequently reinforces the main take-away of the preceding lyrics, creating a coherent brand synergy between sound and semantics.
[39] Although Megan is referencing well-established conventions with her vocable, she also subverts the semiotic script, stepping over the gendered and racialized boundaries separating “tasteful,” softcore representations of sexual desire with “vulgar,” hardcore sexuality. Specifically, this gesture is a sharp rebuke to what Evelyn Higginbotham (1994, 196) has famously termed “respectability politics”: the goal, originating in the nineteenth century, for Black women to “distance oneself as far as possible from images perpetuated by racist stereotypes”—such as the hypersexual Jezebel archetype—with “no laxity as far as sexual conduct, cleanliness, temperance, hard work, and politeness [are] concerned.” Higginbotham explains that while strategies of respectability were originally devised for the sake of achieving racial parity, they nevertheless often have the effect of coercing Black women into behavioral structures defined by a default white femininity. Megan’s Hot Girl persona, and vocable, fly in the face of these prescriptions.
[40] I also want to acknowledge a key semiotic distinction between Megan’s vocable and earlier connotations of sexualized vocal fry. In contrast to the pornographic context (exemplified by Donna Summer), which foregrounds a teleological arc of arousal and climax that strives for verisimilitude, the [æ] vocable is a single, intense, brief state that does not significantly change from iteration to iteration. Plainly put, it’s not realistic or believable as an actual indicator of libidinal pleasure: people don’t normally go around making [æ] sounds during sex.(24) Instead, as discussed previously, the vocable works through an anti-naturalistic surfeit of exact repetition, often in important parts of the song, thus drawing attention to its own artifice. In fact, the vocable is often sampled, the signal technology of verbatim repetition.(25) As Corbett and Kapsalis (1996, 106) note, “Like the female orgasm, the technology of sampling is not subject to the generational ‘exhaustion’ of analog technology, but digitally replicates and proliferates the original text.” In Peircian semiotic terms, earlier treatments of sexualized vocal fry tend to function as an index—a vocal sound that plausibly accompanies sexual pleasure, like smoke betokening fire—but the vocable in this context is an icon, a sound that literally, phonetically resembles something sexually suggestive (a protruding tongue) but is not, in fact, connected to the felt dynamics of erotic excitement, or its simulation. And crucially, this isn’t just anybody’s tongue, but Megan Thee Stallion’s tongue, an intentional, crafted stand-in for her public persona and the Hot Girl ethos she embodies. The creaky [æ] vocable isn’t just a sonic icon. It’s a sonic trademark of her brand.
Real Hot Girl Shit: Vocable as Timbre Trademark
[41] When discussing pop music celebrity, Mark C. Samples (2016, 290) notes that “brand is not a thing or a person, but something in between: a brand persona.
Audio Example 6. Five examples of Megan Thee Stallion’s trademark (from “Captain Hook,” “B.I.T.C.H.,” “Ain’t Equal,” “Outside,” and “Ratchet,” respectively)
[42] The branding function of the vocable is plainest to see in a gesture that appears in the intros or outros to several of her songs: out of synchronization with the beat (or before it enters), she declares “real Hot Girl shit” in immediate proximity to the [æ] vocable, similar to the naming practices of DJ Khaled (“another one”), Nicki Minaj (“young money”), and other musicians. Audio Example 6 presents five of these moments. In explicitly grafting Hot Girl identity onto the vocable, it’s as if she’s stamping her brand with a sonic trademark.
[43] This isn’t just a cute analogy. As stated in the Lantham Act of 1946 (15 U.S. Code § 1127), the statutory law that formally established a national system of trademark registration, a trademark may consist of “any word, name, symbol, or device
[44] What does the Hot Girl-branded trademark represent? Samples (2016) suggests that artists’ brands are often unified by a coherent set of values or themes, often referred to colloquially as being “on brand.” Illustrating this point, he identifies three core elements of Swedish opera singer Jenny Lind’s brand persona during her American tour in the mid-1800s: celebrity, artistry, and charity. Similarly, as we have seen, there are three main characteristics of Megan’s persona that pervade her music and imagery, all of which figure prominently in the lyrical content immediately abutting the [æ] vocable (Example 13). First, the Hot Girl is powerful, proud, defiant, self-possessed, combative, and individualistic—a bad bitch. “Fuck bein’ good, I’m a bad bitch,” she tells us before making her [æ] vocable in “Girls in the Hood” (0:03); “badder than your favorite bad bitch,” she brags before intoning the vocable in “What’s New” (0:04). This bad bitch swagger is related to the “Sista with Attitude” archetype identified by Cheryl Keyes (2002, 200) in rap personas of the ‘80s and early ‘90s, the first generation to “reclaim the word ‘bitch,’ viewing it as positive rather than negative and using the title to entertain or provide cathartic release.” It’s also connected to the modern sensibility of “ratchet,” an originally derogatory term that, like “bitch,” has been recently reclaimed by some to denote flamboyant, shamelessly “ghetto-fabulous” styles and behaviors. In the context of Black female performers, Therí Pickens (2015, 44) defines ratchet as a “performance of excess
[45] Second, as previously discussed, her persona and vocable are unabashedly sexual, a sensibility that emphasizes her erotic power and doesn’t flinch from explicitly articulating the persona’s carnal appetites and sex-positive attitude. As The Guardian noted of “WAP,” this sensibility is “unapologetic in celebrating the sensuality and sexuality of women. It isn’t shy or coy, it’s about the loud articulation of female desire for sex, as they want it, and it centers them as active participants with agency” (McClinton 2020). Crucially, Hot Girl sexuality is quite different from dressing and acting provocatively for the purpose of attracting heterosexual male attention, historically the default branding option of most female pop celebrities (Lieb 2013). In a guest essay for the New York Times, Megan Thee Stallion (2020) describes this attitude: “I choose what I wear, not because I am trying to appeal to men, but because I am showing pride in my appearance, and a positive body image is central to who I am as a woman and a performer.” There’s an implicit political edge to this stance. She continues: “many [assume] that I’m dressing and performing for the male gaze. When women choose to capitalize on our sexuality, to reclaim our own power
Example 14. Megan Thee Stallion, “Rich” (2020), chorus (0:27–0:45)

(click to enlarge, see the rest, and listen)
[46] Finally, Megan’s brand persona emphasizes financial independence. Her persona is rich by virtue of her own talent and hard work; she is wealthy and successful without the help of a man. “Rich,” from the Suga EP (2020), features a chorus that sums up this stance (Example 14): in addition to lyrics extolling self-determination and control over her money, she includes an ad-lib vocal track that hits offbeats with percussive vocables (“ya,” “hey,” “baow”), echoes the main vocal in call-and-response (“money on my own”), and formally delineates the two 4-bar hypermeters of the chorus with prominently mixed [æ] vocables (in blue).
[47] These three brand themes (bad bitch, sexual, rich) aren’t unique to Megan. However, she bundles them all together in one savvy, split-second timbre trademark that seems tailor-made for the speed and immediacy of today’s always-online cultural moment. Indeed, the creaky [æ] vocable is a crossmodal soundbite that affords splicing, parody, and recombination by users, who then share such content online on ever-shifting platforms such as TikTok, Twitter, Instagram, YouTube, and other digital media (witness Video Example 2). As Kristin Lieb (2013, 7) notes, “The pace of communication, accelerated by 24-hour television news cycles and the 24-hour social cycle offered by the Internet and widely adopted social media platforms, has compelled [female] celebrities to strategize continuously to remain culturally relevant,” including the increasing need to “achieve cultural resonance quickly and deeply” (16, emphasis original). In this regard, the timbre trademark has obvious advantages as a branding strategy. Listeners process timbre very quickly, independently of conscious awareness (Fales 2002; Wallmark 2022). This rapidity means that the vocable can establish a brand persona quickly and efficiently, without extensive cognitive mediation. (Listeners unfamiliar with her, moreover, can still access the semiotic associations consonant with the Hot Girl persona through its sociophonetic implications and iconicity, even if this doesn’t trigger a specific brand identification.) Imperatively, the vocable enables immediate identification of a song as belonging to her. Since streaming services only count a stream as a “play” if it exceeds thirty seconds, this payment model favors artists who are able to establish a quick connection with audiences and motivate them to keep listening. The majority (57%) of Megan’s songs as leader feature at least one occurrence of the [æ] vocable in the first thirty seconds, and around a quarter (23%) of her guest or featured artist tracks do the same (including the wildly popular “WAP”).
Example 15. Association between frequency of [æ] vocables (y-axis) in each song and total Spotify streams (x-axis)

(click to enlarge)
[48] The timbre trademark is a core part of Megan’s persona and branding, ultimately motivated by a desire for recognition and revenue (brand value). Is there an observable relationship between the prevalence of the vocable and a song’s popularity? Or, put more bluntly, is her sonic branding strategy working? Popularity is a notoriously fuzzy quality to measure, but several metrics can be useful proxies, including YouTube views and streams on services such as Spotify. Since these metrics are captured in the [æ] microcorpus, the microcorpus can address whether the timbre trademark predicts success. Spotify and YouTube streams are highly correlated, so we can focus here on just one of these two measures. Example 15 plots the relationship: the points represent each of Megan’s 79 songs (excluding guest tracks), with count of [æ] vocable on the y-axis and total Spotify streams (log transformed to normal distribution) on the x-axis. The outlier track “Body,” for example, is the dot in the upper righthand corner. Sure enough, there is a moderate positive correlation between density of the [æ] vocable and Spotify streams (as of November 2021), as reflected in the regression line (shaded area indicates standard error of the mean).(28) A linear regression model indicates that for roughly every 3.25 [æ] vocables in a song, streams increase by one million. To be clear, we must be cautious in interpreting this, or any, model.(29) The count of vocables explains only 11% of total variability in streaming, which, while statistically significant, still leaves out most of the model variance. Nevertheless, the evidence is suggestive: Megan’s timbre trademark helps forge an immediate brand recognition that translates into increased audience engagement.
[49] This relationship motivates one final question. Given its association with the success of Megan’s brand persona, have any copycat rappers infringed upon her “trademark,” so to speak? The three core attributes of the Hot Girl brand do not belong exclusively to Megan; neither, most likely, does the “brand tone” of her rapping voice. All singers may credibly make the claim of vocal distinctiveness, though only in rare instances—Bette Midler in 1988, Tom Waits in 1992—do these claims hold up in court (Samples 2018). However, the [æ] vocable is subtly but significantly different. I’ve argued that, in contrast to indexical brand tones such as Waits’s, which tell us that the voice belongs to the Tom Waits persona through association, the [æ] vocable is indelibly linked to Megan’s Hot Girl persona at more of an iconic level of semiosis. It literally, phonetically resembles her signature tongue gesture. Hence, the repeated use by another rapper of this specific [æ] vowel with vocal fry may betoken an unauthorized, iconic reference to the Hot Girl persona.
[50] Enter Dallas rapper Erica Banks, who released her self-titled debut on the label 1501 Certified Entertainment in the summer of 2020, just months after Megan acrimoniously ended her relationship with the label. Social media critics were quick to point out similarities between the two and castigate the label for signing a “fake” Megan. Both Banks and Megan dismissed these critiques, pointing out the commonalities in Texan accent and the misogynistic tendency of commentators to pit female artists against one another. Nevertheless, the comparisons persisted. As one fan tweeted, “It’s not the accent, we could care less about that, but when you have the same flow, style, ad libs, and delivery it could come off as a bit copy cat-ish.” Another commented, “saying ‘aye’ and ‘uh’ etc. etc.
Audio Example 7. Erica Banks, “Buss It” (2020) chorus (0:08–0:28)
[51] Erica Banks’s top single, “Buss It,” indeed features a recurring ad-lib vocable that strongly resembles Megan’s. Banks uses pronounced vocal fry with the [æ] vowel, but it’s quite a bit longer (approximately 1s) and features an initial voiceless /h/ consonant [hæ] (Audio Example 7). Banks’s [hæ] vocable occurs 11 times throughout the song, and, like Megan’s, is either sampled or performed with a high degree of consistency across occurrences. While the characteristic timbre shares certain obvious similarities with the [æ] vocable, however, Banks’s patterns of usage diverge in striking ways. In contrast to Megan’s overwhelming use of anticipatory fourth-position syncopation to delineate the 4-bar hypermeter, the [hæ] vocable in “Buss It” occurs mainly on the strong parts of the hypermeter (beats 1 and 3). Only two instances of the vocable are clearly percussive—a statement on the upbeat of beat 2 in m. 1 (position 4/32) in the two verses—and only one is formal (position 1/32 in the chorus, transitioning after the first verse). Basically half (6 out of 11) occur on beat 3. In stark contrast, across the microcorpus, beat 3 placement of the [æ] vocable is practically nonexistent: it never occurs in m. 1 (position 5/32) or m. 3 (position 21/32), and combined occurrences in m. 2 (position 13/32) and m. 4 (position 29/32) amount to less than 1% of the total corpus. In sum, while there are plain reasons why some listeners hear Banks’s creaky [hæ] vocable as a copycat gesture, it’s strategically differentiated enough in phonetic composition and placement to make a reasonable forensic case that any superficial resemblances are coincidental. This might suggest that Banks and/or her producer (Sgt. J) are aware of the connotations of the creaky [æ] trademark, and, although wanting to evoke some qualitative features of the successful brand it represents, are also careful not to flagrantly step on Megan’s toes.
Conclusion
[52] Timbre plays a vital but undertheorized role in rap vocality. By defaulting to poetic and rhythmic structures as the sole bearer of meaning in the rapped voice, we risk obscuring the phatic, non-verbal elements that serve as a potent though often invisible structuring and semiotic force in hip-hop expression and politics. As a case study, drawing on a microcorpus of instances of Houston rapper Megan Thee Stallion’s creaky voice [æ] vowel (699 instances over 101 songs), I’ve argued that vocables can perform both percussive and form-bearing functions in rap. The majority of formal [æ] vocables are anticipatory fourth-position syncopations (Temperley 2021) occurring on the final eighth-note of the 4-bar hypermeter. Loosely applying the integrative analytical model I developed elsewhere (Wallmark 2022), this article traces the phonetics, acoustics, crossmodal implications, and musical functions of the [æ] vocable, then situates these observations in a broader sociohistorical theater. I claim that Megan systematically uses her vocable as a timbre trademark: a unique, memorable, and immediately recognizable sonic icon of her brand persona organized around three coherent themes (a bad bitch who is sexual and rich). This brand is closely associated with the gendered and racialized cultural history of vocal fry in representations of female sexual pleasure. As James Q. Davies (2015, 681) explains, “voice connects to political ontologies of the here and now, human relations, and our shared materiality today. It relates intimately not only to nature and our bodies but also to the fight over what that nature is.” Accordingly, vocal timbre in rap—as exemplified by the [æ] vocable—is replete with social meanings that cannot be severed from their musical functions. In certain instances, as documented here, timbre is a discursive battlefield upon which rappers negotiate contested claims of identity and power within a commercially and technologically mediated context.
Audio Example 8. Cardi B feat. Megan Thee Stallion, “WAP” (2020), 2:09–2:19
[53] In closing, I’d like to briefly return to the “deliciously filthy” song that opened this article. Although the lyrics to “WAP”—not to mention its looping “whores in this house” sample—are blatantly explicit, there are other non-verbal elements that work hand-in-glove with the semantic content of the song to viscerally reinforce and amplify these sexually explicit meanings. Megan’s [æ] vocable is phonetically filthy—it activates a crossmodal, iconic representation of a protruding tongue, a branded meaning structure that is further enlivened through connections to sex via the semiotics of vocal fry. The vocable is presented at structurally important points of the song (e.g., transitioning between verse and chorus, when the bass drops an octave). The musical context, moreover, is consonant with this broader reading: “WAP” features a slinky three-note chromatic bassline (repeating B-C-
Zachary Wallmark
University of Oregon
961 E. 18th Ave.
Eugene, OR 97403
zwallmar@uoregon.edu
Works Cited
AceShowBiz. 2020. “Erica Banks Responds to Being Called ‘Fake’ Megan Thee Stallion.” AceShowBiz, June 20, 2020. https://www.aceshowbiz.com/news/view/00155604.html.
Adams, Kyle. 2008. “Aspects of the Music/Text Relationship in Rap.” Music Theory Online 14 (2). https://doi.org/10.30535/mto.14.2.3.
—————. 2009. “On the Metrical Techniques of Flow in Rap Music.” Music Theory Online 15 (5). https://doi.org/10.30535/mto.15.5.1.
Anderson, Rindy C., Casey A. Klofstad, William J. Mayew, and Mohan Venkatachalam. 2014. “Vocal Fry May Undermine the Success of Young Women in the Labor Market.” PLOS ONE 9 (5): e97506. https://doi.org/10.1371/journal.pone.0097506.
Bowen, Sesali. 2019. “Twitter Has Given Megan Thee Stallion An Official Emoji.” Nylon. https://www.nylon.com/megan-thee-stallion-twitter-emoji.
Bradley, Adam. 2009. Book of Rhymes: The Poetics of Hip-Hop. Basic.
Bradley, Regina. 2021. Chronicling Stankonia: The Rise of the Hip-Hop South. University of North Carolina Press.
Burton, Justin Adams. 2017. Posthuman Rap. Oxford University Press. https://doi.org/10.1093/oso/9780190235451.001.0001.
Caldwell, Brandon. 2020. “Dallas Rapper Erica Banks Brushed Off Megan Thee Stallion Copycat Accusations.” HipHopDX, June 20, 2020. https://hiphopdx.com/news/id.56454/title.dallas-rapper-erica-banks-brushes-off-megan-thee-stallion-copycat-accusations#.
can i help you. 2020. “What’s up It’s AH! Aka AH! // Megan Thee Stallion Meme.” YouTube video, 00:00:11. https://www.youtube.com/watch?v=Boic102QNDk.
Catford, John C. 1964. “Phonation Types: The Contribution of Some Laryngeal Components of Speech Production.” In In Honor of Daniel Jones: Papers Contributed on the Occasion of His Eightieth Birthday, 12 September 1961, ed. David Abercrombie, Dennis Butler Fry, Peter MacCarthy, Norman Carson Scott, and J.L.M. Trim, 26–37. Longmans.
Chappell, Whitney, John Nix, and Mackenzie Parrott. 2020. “Social and Stylistic Correlates of Vocal Fry in A Cappella Performances.” Journal of Voice 34 (1): 156.e5-156.e13. https://doi.org/10.1016/j.jvoice.2018.06.004.
Coates, Jennifer. 2015. Women, Men and Language: A Sociolinguistic Account of Gender Differences in Language. Routledge. https://doi.org/10.4324/9781315835778.
Condit-Schultz, Nathaniel. 2016. “MCFlow: A Digital Corpus of Rap Transcriptions.” Empirical Musicology Review 11 (2): 124–47. https://doi.org/10.18061/emr.v11i2.4961.
Corbett, John, and Terri Kapsalis. 1996. “Aural Sex: The Female Orgasm in Popular Sound.” The Drama Review 40 (3): 102–11. https://doi.org/10.2307/1146553.
Dallaston, Katherine, and Gerard Docherty. 2020. “The Quantitative Prevalence of Creaky Voice (Vocal Fry) in Varieties of English: A Systematic Review of the Literature.” PLOS ONE 15 (3): e0229960. https://doi.org/10.1371/journal.pone.0229960.
Davies, James Q. 2015. “Voice Belongs.” Colloquy: Why Voice Now? Convened by Martha Feldman, Journal of the American Musicological Society, 68 (3): 677–81.
Durham, Aisha, Brittney C. Cooper, and Susana M. Morris. 2013. “The Stage Hip-Hop Feminism Built: A New Directions Essay.” Signs: Journal of Women in Culture and Society 38 (3): 721–37. https://doi.org/10.1086/668843.
Eidsheim, Nina Sun. 2019. The Race of Sound: Listening, Timbre, and Vocality in African American Music. Duke University Press. https://doi.org/10.1215/9781478090359.
Fagen, Lucas. 2019. “Megan Thee Stallion, a Hardcore Master of Rap.” Hyperallergic, August 31, 2019, sec. Music. https://hyperallergic.com/515327/megan-thee-stallion-a-hardcore-master-of-rap/.
Fales, Cornelia. 2002. “The Paradox of Timbre.” Ethnomusicology 46 (1): 56–95. https://doi.org/10.2307/852808.
Fink, Robert. 2005. Repeating Ourselves: American Minimal Music as Cultural Practice. University of California Press. https://doi.org/10.1525/9780520938946.
Fox, Aaron A. 2004. Real Country: Music and Language in Working-Class Culture. Duke University Press. https://doi.org/10.1515/9780822385998.
Grewal, Sara Hakeem. 2020. “Hip Hop and the University: The Epistemologies of ‘Street Knowledge’ and ‘Book Knowledge.’” Journal of Popular Music Studies 32 (3): 73–97. https://doi.org/10.1525/jpms.2020.32.3.73.
Habasque, Pierre. 2019. “Framing ‘Female’ Vulgarity: An Example of the Use of Linguistic Markers in an Episode of NBC’s Parks and Recreation.” Genre En Séries: Cinéma, Télévision, Médias 10. https://doi.org/10.4000/ges.739.
Heidemann, Kate. 2016. “A System for Describing Vocal Timbre in Popular Song.” Music Theory Online 22 (1). https://doi.org/10.30535/mto.22.1.2.
Henton, Caroline, and Anthony Bladon. 1988. “Creak as a Sociophonetic Marker.” In Language, Speech, and Mind: Studies in Honour of Victoria A. Fromkin, ed. Larry M. Hyman and Charlies N. Li, 3–29. Routledge.
Higginbotham, Evelyn Brooks. 1994. Righteous Discontent: The Women’s Movement in the Black Baptist Church, 1880–1920. Harvard University Press.
Hirjee, Hussein, and Daniel Brown. 2010. “Using Automated Rhyme Detection to Characterize Rhyming Style in Rap Music.” Empirical Musicology Review 5 (4): 121–45. https://doi.org/10.18061/1811/48548.
Hollien, Harry. 1974. “On Vocal Registers.” Journal of Phonetics 2 (2): 125–43. https://doi.org/10.1016/S0095-4470(19)31188-X.
Holmes, Charles. 2020. “Megan Thee Stallion: The ‘Rolling Stone’ Interview.” Rolling Stone, February 27, 2020. https://www.rollingstone.com/music/music-features/megan-thee-stallion-interview-hot-girl-summer-950292/.
Huron, David. 2013. “On the Virtuous and the Vexatious in an Age of Big Data.” Music Perception 31 (1): 4–9. https://doi.org/10.1525/mp.2013.31.1.4.
Joyner, Charles W. 1999. Shared Traditions: Southern History and Folk Culture. University of Illinois Press.
Keyes, Cheryl L. 2002. Rap Music and Street Consciousness. University of Illinois Press.
Komaniecki, Robert. 2020. “Vocal Pitch in Rap Flow.” Intégral 34: 25–45. https://www.esm.rochester.edu/integral/34-2020/komaniecki/.
Krims, Adam. 2000. Rap Music and the Poetics of Identity. Cambridge University Press.
Lacasse, Serge. 2010. “Slave to the Supradiegetic Rhythm: A Microrhythmic Analysis of Creaky Voice in Sia’s ‘Breathe Me.’” In Musical Rhythm in the Age of Digital Reproduction, ed. Anne Danielsen, 141–55. Routledge. https://doi.org/10.4324/9781315596983-9.
Laver, John. 1994. Principles of Phonetics. Cambridge University Press. https://doi.org/10.1017/CBO9781139166621.
Lewis, George E. 1996. “Improvised Music Since 1950: Afrological and Eurological Forms.” Black Music Research Journal 16 (1): 91–119. https://doi.org/10.2307/779379.
Lieb, Kristin J. 2013. Gender, Branding, and the Modern Music Industry: The Social Construction of Female Popular Music Stars. Routledge. https://doi.org/10.4324/9780203071786.
Love, Bettina L. 2012. Hip Hop’s Li’l Sistas Speak: Negotiating Hip Hop Identities and Politics in the New South. Peter Lang.
Malawey, Victoria. 2020. A Blaze of Light in Every Word: Analyzing the Popular Singing Voice. Oxford University Press. https://doi.org/10.1093/oso/9780190052201.001.0001.
Manabe, Noriko. 2019. “We Gon’ Be Alright? The Ambiguities of Kendrick Lamar’s Protest Anthem.” Music Theory Online 25 (1). https://doi.org/10.30535/mto.25.1.9.
McClary, Susan. 1991. Feminine Endings: Music, Gender, and Sexuality. University of Minnesota Press.
McClinton, Dream. 2020. “Cardi B and Megan Thee Stallion’s WAP Should Be Celebrated, Not Scolded.” The Guardian, August 12, 2020. http://www.theguardian.com/music/2020/aug/12/cardi-b-megan-thee-stallion-wap-celebrated-not-scolded.
Megan Thee Stallion. 2020. “Why I Speak Up for Black Women.” The New York Times, October 13, 2020, sec. Opinion. https://www.nytimes.com/2020/10/13/opinion/megan-thee-stallion-black-women.html.
Moore, Allan F. 2012. Song Means: Analysing and Interpreting Recorded Popular Song. Routledge.
Morgan, Joan. 1999. When Chickenheads Come Home to Roost: A Hip-Hop Feminist Breaks It Down. Simon & Schuster.
Neal, Mark Anthony. 1999. What the Music Said: Black Popular Music and Black Public Culture. Routledge.
Ohriner, Mitchell. 2017. “Metric Ambiguity and Flow in Rap Music: A Corpus-Assisted Study of Outkast’s ‘Mainstream’ (1996).” Empirical Musicology Review 11 (2): 153–79. https://doi.org/10.18061/emr.v11i2.4896.
—————. 2019. Flow: The Rhythmic Voice in Rap Music. Oxford University Press. https://doi.org/10.1093/oso/9780190670412.001.0001.
Pecknold, Diane. 2016. “‘These Stupid Little Sounds in Her Voice’: Valuing and Vilifying the New Girl Voice.” In Voicing Girlhood in Popular Music, ed. Jacqueline Warwick and Allison Adrian, 77–98. Routledge.
Pennock-Speck, Barry. 2005. “The Changing Voice of Women.” In Actas Del XXVIII Congreso Internacional de AEDEAN, ed. J.J.C. Garcia de Leonardo, Jesús Tronch Perez, Milagros del Saz Rubio, Carme Manuel Cuenca, Barry Pennock-Speck, and Maria José Coperías Aguilar, 407–15. University of Valencia.
Pickens, Therí A. 2015. “Shoving Aside the Politics of Respectability: Black Women, Reality TV, and the Ratchet Performance.” Women & Performance: A Journal of Feminist Theory 25 (1): 41–58. https://doi.org/10.1080/0740770X.2014.923172.
Poyatos, Fernando. 1993. Paralanguage: A Linguistic and Interdisciplinary Approach to Interactive Speech and Sounds. John Benjamins. https://doi.org/10.1075/cilt.92.
Rae, Issa. 2012. “Episode 2 of Ratchetpiece Theatre Featuring Tyga.” Issarae.Com (blog), July 27, 2012. https://blog.issarae.com/post/28137213938/episode-2-of-ratchetpiece-theatre-featuring-tyga.
Ramírez de Arellano, Susanne. 2020. “The New Song ‘WAP’ Is a Joyful Gender Role Reversal. Of Course People Are Mad.” Think, NBC News (website), August 10, 2020. https://www.nbcnews.com/think/opinion/wap-cardi-b-megan-thee-stallion-joyful-role-reversal-no-ncna1236301.
Rose, Tricia. 1994. Black Noise: Rap Music and Black Culture in Contemporary America. Wesleyan University Press.
Samples, Mark C. 2016. “The Humbug and the Nightingale: P. T. Barnum, Jenny Lind, and the Branding of a Star Singer for American Reception.” The Musical Quarterly 99 (3–4): 286–320. https://doi.org/10.1093/musqtl/gdx009.
—————. 2018. “Timbre and Legal Likeness: The Case of Tom Waits.” In The Relentless Pursuit of Tone: Timbre in Popular Music, ed. Robert Fink, Melinda Latour, and Zachary Wallmark, 119–40. Oxford University Press.
Shange, Savannah. 2014. “A King Named Nicki: Strategic Queerness and the Black Femmecee.” Women & Performance: A Journal of Feminist Theory 24 (1): 29–45. https://doi.org/10.1080/0740770X.2014.901602.
Silver, Nate. 2012. The Signal and the Noise: Why So Many Predictions Fail—But Some Don’t. Penguin.
Ski, Frank. 1993. “Whores in this House.” Deco Records DEC-0013, 12-inch vinyl.
Southern, Eileen. 1983. Music of Black Americans. 2nd ed. W.W. Norton.
Stratton, Jon. 2014. “Coming to the Fore: The Audibility of Women’s Sexual Pleasure in Popular Music and the Sexual Revolution.” Popular Music 33 (1): 109–28. https://doi.org/10.1017/S026114301300055X.
Temperley, David. 2021. “The Origins of Syncopation in American Popular Music.” Popular Music 40 (1): 18–41. https://doi.org/10.1017/S0261143021000283.
Tidal. 2020. “Megan Thee Stallion & Longtime Producer, LilJuMadeTheBeat, on Friendship and Making ‘Good News.’” YouTube video, 00:13:27. https://www.youtube.com/watch?v=MZn6cknTa5A.
Wallmark, Zachary. 2022. Nothing but Noise: Timbre and Musical Meaning at the Edge. Oxford University Press. http://doi.org/10.1093/oso/9780190495107.001.0001
Williams, Linda. 2008. Screening Sex. Duke University Press.
Wilson, Olly. 1999. “The Heterogeneous Sound Ideal in African-American Music.” In Signifyin(g), Sanctifyin’, and Slam Dunking: A Reader in African-American Expressive Culture, ed. Gena Dagel Caponi, 157–71. University of Massachusetts Press.
Woldu, Gail Hilson. 2006. “Gender as Anomaly: Women in Rap.” In The Resisting Muse: Popular Music and Social Protest, ed. Ian Peddie, 89–102. Routledge. https://doi.org/10.4324/9781351218061-7.
Wolf, Naomi. 2015. “Young Women, Give up the Vocal Fry and Reclaim Your Strong Female Voice.” The Guardian, July 24, 2015. https://www.theguardian.com/commentisfree/2015/jul/24/vocal-fry-strong-female-voice.
Yuasa, Ikuko P. 2010. “Creaky Voice: A New Feminine Voice Quality for Young Urban-Oriented Upwardly Mobile American Women?” American Speech 85 (3): 315–37. https://doi.org/10.1215/00031283-2010-018.
Footnotes
* I wish to thank Mark Samples, Drew Nobile, Abigail Fine, Morgan Bates, Marie Wallmark, and the University of Oregon graduate students in my fall 2021 timbre seminar for helpful discussion and comments on an earlier draft of this article; Victoria Malawey and Kyle Adams for generous and constructive reviews; and Mitch Ohriner and Brad Osborn for their editorial guidance and thoughtful copyediting.
Return to text
1. In this article I use the terminology “ad lib,” which generally refers to the off-the-cuff, improvisatory vocal elements that ornament rap songs. However, I argue that Megan Thee Stallion treats this particular vocable with far greater premeditation and systematicity than the word “ad lib” might suggest.
Return to text
2. As noted by Grewal (2020), this privileging of the written word over the performed, musical elements of rapping in academic hip-hop studies may inadvertently reinscribe a Eurocentric, “book knowledge” frame on a Black oral practice that tends to prioritize “street knowledge.”
Return to text
3. Following the precedent of Shange (2014), Burton (2017) and others, hereafter I will abbreviate Megan Thee Stallion as “Megan” to reflect the discursive norms most common among the artist and her fans.
Return to text
4. YouTube user why_am_i_always_hungry? in comments to a video on the can i help you channel, “What’s up it’s AH! aka AH! // Megan Thee Stallion meme” (2020).
Return to text
5. There’s a final point to be made. Despite its significant cultural and commercial impact—not to mention its richly developed phatic elements—Southern rap has long been marginalized from hip-hop scholarship, often considered too repetitive, raunchy, and simplistic to be taken seriously (though see R. Bradley (2021)). Crucially, as well, the scholarly canon of hip-hop consists overwhelmingly of male rappers, obscuring the immense creative contributions of Black female artists. I need to be clear upfront in acknowledging that, as a middle-class, mixed race, male-identifying music scholar from a northern state, it would be ludicrous for me to claim any kind of authority to speak for the artists often excluded from academic hip-hop studies. I also have not yet been able to reach Megan Thee Stallion directly for commentary. Nevertheless, in bringing phatic vocality to the fore, this project aspires to address some of these longstanding biases and omissions.
Return to text
6. The use of standard music notation in the transcription of rap music is not without its considerable limitations; for discussion, see Ohriner (2019, 8). Some scholars have proposed alternate methods of transcription for rap vocals, e.g., Adams (2008, 2009) and Manabe (2019). Nevertheless, acknowledging these inadequacies, I proffer standard notation at points in this article where I believe rhythmic precision helps to make an argument clearer for readers with knowledge of Western music notation. Additionally, all examples and analyses in this article are supported by parallel audio clips, which should be sufficient to illustrate the key points, as the rhythmic designs of the vocable are generally quite audible independent of transcription.
Return to text
7. The terms vocal fry and creaky voice are synonymous and often used interchangeably; here I will mainly use the “fry” terminology.
Return to text
8. The number and definitions of vocal registers have been an ongoing topic of debate among voice scientists. For more details on vocal registers in the context of popular music, see Malawey (2020) and Heidemann (2016).
Return to text
9. YouTube user Moonlight Amajiki in comments to a video on the can i help you channel, “What’s up it’s AH! aka AH! // Megan Thee Stallion meme” (2020).
Return to text
10. This analysis was generated using Praat software.
Return to text
11. In cultural history, the term microhistory refers to investigations that focus on very small units of research (e.g., a specific day, ordinary person, or event) as a window onto broader phenomena. As Joyner (1999, 1) summarizes, it’s “asking large questions in small places.” Adopting this general “micro” orientation, in this article I focus on a very short vocable in the music of one contemporary rapper using a microcorpus of instances of this single phatic gesture spread across a relatively small (though complete) body of recordings.
Return to text
12. YouTube user Nyla Singer in comments to a video on the can i help you channel, “What’s up it’s AH! aka AH! // Megan Thee Stallion meme” (2020).
Return to text
13. In addition to raw counts, the dataset quantifies density of occurrence as ratio of track count to play time, which better accounts for differences in track lengths. However, all the songs in the corpus are similar in length, M track time = 2:49m, SD = 31.4s; consequently, the two measures yield similar results. For this reason, here I only summarize the results of the count data. Readers wishing to compare measures are encouraged to consult the dataset and analysis script.
Return to text
14. In providing local rhythmic and timbral accents to the musical narrative, the percussive function of the vocable is typical of broader Afrodiasporic practices described by Southern (1983) and Wilson (1999). Percussive vocables are also generally much more common than formal vocables within rap songs writ large, though a much broader corpus would be needed to support this contention.
Return to text
15. Though it is often not clear whether a certain vocable is sampled in Megan’s songs, it is revealing that in live performances of “Body” and other songs, the percussive vocable in integrated into the backing track (i.e., Megan is not performing the vocables live).
Return to text
16. For more background on the song’s production, see the conversation between Megan and LilJu on the Tidal channel YouTube video, “Megan Thee Stallion & Longtime Producer, LilJuMadeTheBeat, on Friendship and Making ‘Good News’ (2020).
Return to text
17. Introductions have the highest percentage of vocables unaccompanied by a beat (88%, or 14% of all dropout vocables in the corpus). However, since the beat has not started in this section of the song, I do not classify them here as analogous to the beat dropout.
Return to text
18. In the large national survey study of adults referenced by Wolf (2015), Anderson et al. (2014) reported that vocal fry significantly negatively impacted the perception of a speaker’s trustworthiness, competence, educational attainment, attractiveness, and hireability. Interestingly, that study found that negative judgments in this study were harsher among female listeners compared to male. Relatedly, Chappell et al. (2020) discovered that fry in singing is generally perceived more negatively than modal voice, too, though the sex of the singer and listener age and musical training modulated these perceptions.
Return to text
19. Additionally, as noted by Bettina Love (2012), many of the sexual reference points in Southern rap come from the conventions of stripping and the culture of the strip club.
Return to text
20. The incorporation of erotic groaning and moaning in popular song is much older than pornographic film. As discussed by Corbett and Kapsalis (1996, 105), it can be traced back to female blues artists of the 1920s and 1930s, e.g., Ma Rainey’s “Deep Moaning Blues” (1928) and Victoria Spivey’s “Moaning the Blues” (1934). However, these early recordings do not include vocal fry. An important model for the creaky-voiced sexual groan is Ray Charles’s “What’d I Say” (1959), which features an ad-libbed call-and-response section between Charles and the Raelettes at 5:25–5:36; Stratton (2014, 121–3) argues that this moment (and others) represents a secular transposition of vocal techniques originally developed to represent religious ecstasy in the Black church. It should also be mentioned here that, while these sexual vocalizations likely originated in Black popular forms, they are in no way restricted to them; notable in this regard, for example, is Brigitte Bardot and Serge Gainsbourg’s “Je t’aime moi non plus” (1967), most strikingly at 2:32–2:50, and Gainsbourg’s recording with Jane Birkin in 1969 (approximately same time marks).
Return to text
21. Somewhat coincidentally for this article, Sylvia Robinson was the entrepreneuring mastermind behind Sugar Hill Gang’s “Rapper’s Delight” (1979), the first major commercial rap song.
Return to text
22. As in many commercially mediated musical contexts, it’s not immediately clear the extent to which the artist herself had agency over these decisions, and how much of the performance can be attributed to the will of the producer (Giorgio Moroder). As documented by Stratton (2014, 119–20), it was Summer’s idea to “make [her] own” version of Gainsbourg and Birkin’s “Je t’aime moi non plus,” which was rising in the charts at the time owing in no small part to its erotic vocalizations (see endnote 20). However, at the recording session, she became uncomfortable performing these sounds in front of people in the studio. “It was just too personal,” she later confessed, and admitted to never listening to it afterward.
Return to text
23. For more on the gender dynamics of hip-hop, see the classic accounts of Rose (1994), Morgan (1999), and Keyes (2002); on the rise of the subversive “Queen Bitch” archetype, see Woldu (2006).
Return to text
24. An exception here might appear to be the sound’s connotations of gagging or choking, which, when thus read, carry not-so-subtle BDSM implications. Listeners are aware of these connotations: YouTube commenter adiel14ismoody, for instance, described Megan Thee Stallion as “the gagging queen”; see video on the can i help you channel, “What’s up it’s AH! aka AH! // Megan Thee Stallion meme” (2020). Megan Thee Stallion makes this association explicit as well in the first verse of “Savage (Remix)” (2020), with the line at 0:23, “Haters keep my name in they mouth now they gagging,” followed by three percussive [æ] vocables.
Return to text
25. There is precedent in rap production for the sampling of sexually suggestive vocal fry, either from porn films or music recordings. For example, the beat to Digital Underground’s “Freaks of the Industry” (1990) features a looping sample of Donna Summers moaning. I thank Kyle Adams for pointing me to this song.
Return to text
26. See section 1202.15 of the USPTO Trademark Manual of Examining Procedure (July 2021).
Return to text
27. The “d’oh!” sound was registered by Twentieth Century Fox in 2004 (US Patent registration #3411881).
Return to text
28. There is a moderate positive correlation between vocable count and streams, r(77) = .36, p < .001, 95% CI [.15, .53]. A linear regression model indicates that vocable counts significantly predict number of streams, b = 3.25, SE = 0.98, t = 3.34, p < .001, adjusted R2 = .11. It should also be noted here that removing the outlier “Body” from the analysis still produces a statistically significant model. An exploratory model predicting YouTube plays from count data gives similar results (see analysis script), though this was to be expected given the high correlation between these measures. Note that this analysis is necessarily transitory, as Spotify streaming data is always changing.
Return to text
29. As the statistical adage (often attributed to George Box) goes, “All models are wrong, but some are useful.”
Return to text
30. Compiled tweets related to the Erica Banks copycat accusations can be found, respectively, at AceShowBiz (2020) and HipHopDX (Caldwell 2020).
Return to text
Copyright Statement
Copyright © 2022 by the Society for Music Theory. All rights reserved.
[1] Copyrights for individual items published in Music Theory Online (MTO) are held by their authors. Items appearing in MTO may be saved and stored in electronic or paper form, and may be shared among individuals for purposes of scholarly research or discussion, but may not be republished in any form, electronic or print, without prior, written permission from the author(s), and advance notification of the editors of MTO.
[2] Any redistributed form of items published in MTO must include the following information in a form appropriate to the medium in which the items are to appear:
This item appeared in Music Theory Online in Volume 28, Issue 2 in June 2022. It was authored by Zachary Wallmark (zwallmar@uoregon.edu), with whose written permission it is reprinted here.
[3] Libraries may archive issues of MTO in electronic or paper form for public access so long as each issue is stored in its entirety, and no access fee is charged. Exceptions to these requirements must be approved in writing by the editors of MTO, who will act in accordance with the decisions of the Society for Music Theory.
This document and all portions thereof are protected by U.S. and international copyright laws. Material contained herein may be copied and/or distributed for research purposes only.

Prepared by Andrew Eason, Editorial Assistant
Number of visits:
22467